Going Differentially Private: techniques and tools of the trade (Part 2/2)
In the first part of this article, you had your first encounter with Differential Privacy and learned why it’s so awesome. In this second part, we’ll present to you three python libraries for implementing Differential Privacy: Difflibpriv, TensorFlow-Privacy and Opacus.

The rapid adoption of Differential Privacy by Machine Learning practitioners coupled with the high demand for privacy preserving Machine Learning models have both led to the emergence of new software tools and frameworks that aim to ease the design and implementation of such models.
Whether you're a machine learning veteran or just a curious data enthusiast, starting from scratch sounds like a daunting thought. Moreover, you might get lost while scouring Github repositories looking for a solution to start from.
Luckily, we’ve done the heavy lifting for you, and we stumbled upon three libraries for working with Machine learning under Differential Privacy. We will present the features and shortcomings of each of the three libraries. For an effective comparison we’ll focus on the following aspects:
● Community support and ongoing contributions/updates: this is particularly important if you're planning on adopting a long term solution into your projects. Besides, the sight of a dead Github repo is sad.
● Documentation: accessibility is important
● Implementation of different Differential Privacy mechanisms
● Compatibility and integration with mainstream ML libraries such as pytorch, keras and scikit-learn
● Model variety: it’s essential that these libraries offer support for several types of machine learning models
Before we proceed to our comparative analysis, you should keep a few remarks in mind:
At the time of writing of these lines, these are the 3 libraries that we deemed worth experimenting with in the context of Differentially Private Machine Learning. This list is by no means exhaustive. As this field is not fully mature yet and evolving at a fast pace, you should keep an eye out for new tools and frameworks in the near future
We solely focus on software solutions written in the Python programming language, as it's still the best fit for Machine Learning and AI based projects
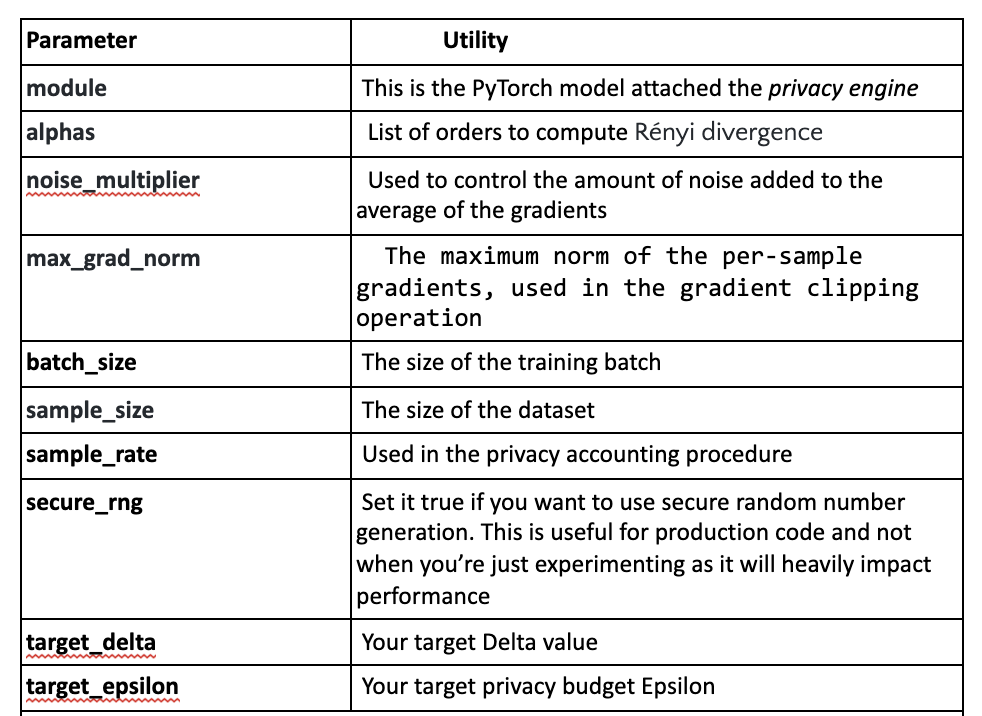
A quick disclaimer: for each library, we’ve included a table that contains explanations for privacy parameters and their usage. However, the official documentation remains the go-to reference. Libraries get updated at one point in the future and the information in these tables will consequently become obsolete (some variables will have been renamed, refactored or dropped, etc.)

1- Diffprivlib
● The IBM Differential Privacy Library, this is a general purpose, open source python library for writing Differential Privacy applications.
● The library offers a handful of tutorials that cover most of what it has to offer in terms of functionality
● The library offers implementations for several supervised and unsupervised machine learning algorithms:
| The model | Base class | Privacy Parameters | Reference Paper |
|---|---|---|---|
| K-means | sklearn.cluster.KMeans | Epsilon, Bounds of the data, accountant (optional) | "Differentially private k-means clustering." |
| Bayes Classifier | sklearn.naive_bayes.GaussianNB | Epsilon, Bounds of the data(min,max), accountant(optional) | "Differentially private empirical risk minimization." |
| Logistic Classifier | sklearn.linear_model.LogisticRegression | Functional Mechanism: Regression Analysis under Differential Privacy” | "Differentially private naive bayes classification" |
| Linear Regression | sklearn.linear_model.LinearRegression | Epsilon, Bounds of the training data (min,max), Bounds of the training labels (min,max) | "Functional Mechanism: Regression Analysis under Differential Privacy” |
| PCA | sklearn.decomposition._pca | Epsilon, Bounds of the data (min,max), max l2 norm of the data | "Symmetric matrix perturbation for differentially-private principal component analysis" |
| Standard Scalar | sklearn.preprocessing.StandardScalar | Epsilon, Bounds of the data(min,max), accountant(optional) | Not specified |
| Explanation |
|---|
| Epsilon: The target privacy budget; it defines the privacy/utility trade-off Bounds of the data(min,max): bounds of the data, either for the entire data or for each feature max l2 norm of the data: the max l2 norm of any row of the data. This defines the spread of data that will be protected by Differential Privacy |