Model distillation and privacy
This blog post is an introduction to the concept of pattern distillation and its link to privacy. It was written by Gijs Barmentlo as part of Data For Good season 8.

Introduction
In recent years deep learning has achieved impressive results on a wide range of tasks including computer vision, natural language processing and speech recognition. However, this performance is achieved with large models that are computationally expensive, which limits their use on mobile devices.
To reduce the size of models we can use model distillation, which is the process of transferring knowledge from a large model, the teacher, to a smaller one, the student. It is possible to do so without significantly decreasing performance because large models do often not use their knowledge capacity fully.
Model distillation – How does it work
a. Basic approach – Learn from the teacher’s soft outputs
First, the cumbersome model is trained on the data. Once trained it will be used as a teacher for a smaller model.
To train the student model we forward propagate the data through both models and use the teacher soft outputs and the ground truths to compute the loss and backpropagate in the student network.
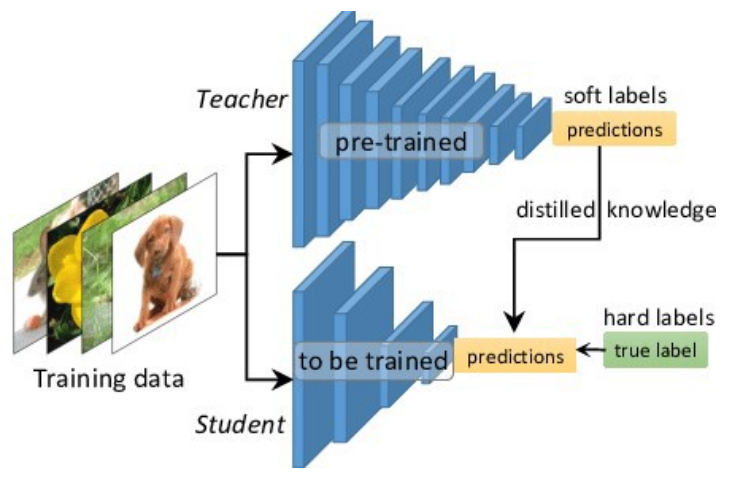
The overall loss function is composed of the student loss, based on the difference between the student prediction and ground truths, and the distillation loss based on the difference between the student and teacher soft outputs
LKD=α*H(y,σ(zs)) +β*H(σ(zt;ρ),σ(zs;ρ))
Where H is the loss function, y is the ground truth label, σ is the softmax function parameterized by the temperature ρ, α and β are coefficients, zs and zt are the logits of the student and teacher respectively.
This method shows the basic intuition behind student-teacher model distillation. However, as it is only based on the teacher’s final output it has convergence issues when applied to deep models.
b. Hint learning – Establish correspondence between layer
Hint learning was proposed to offset this limitation and to add flexibility. It is also known as feature-based distillation because the student learns the teacher’s feature representation as well.

The idea is to add a hint learning loss, based on the difference between the hint and guided layers.
L(FT,FS) =D(TFt(FT),TFs(FS)
Where FT and FS are the hint (teacher) and guided (student) layers. TFT and TFS are transformer and regressor functions which are necessary because FS and FT do not have the same shape. D is a distance function (e.g. L2)
This means a lot of things need to be chosen in order to implement hint learning: the transformer, the regressor, the guided layer and the hint layer. Various methods have been proposed for this, however the lack of theory on how knowledge is transferred makes it hard to evaluate these different methods.
Exemples and performance
BERT, a state-of-the-art NLP model, has successfully been compressed with model distillation. The general architecture of DistilBERT is similar to that of BERT with the token-type embedding and the pooler removed and with half as many layers.
Empirically they found that reducing the number of layers had more impact on computation efficiency than reducing the dimensions of the layers, for a fixed parameter budget.
They used the fact the dimensionality was the same to initialise distilBERT with the weights BERT’s odd layers.
In terms of performance DistilBERT retains 97% of BERT’s performance on the GLUE benchmark while having 40% less parameters and having a 39% shorter inference time
Mobile deployment and privacy issues
a. Privacy and intellectual property concerns
In practice app developers will often collect data from their user to train their DNN, some of which could be sensitive data. Releasing a model trained on this data available could poses privacy issues because an adversary could recover data encoded in the model (Abadi et al. 2016)
In addition, releasing the DNN models opens the possibility of piracy and poses a threat to the developer’s intellectual property
b. A proposed solution – RONA Framework
The RONA framework, for pRivate mOdelcompressioN frAmework, combines student-teacher learning and differential privacy to train models that are both light and secure.
RONA uses 3 main modules : model compression based on knowledge distillation, differentially private knowledge perturbation and query sample selection.

There are some particularities to this framework that help ensure privacy:
The teacher is trained using the public and sensitive data but the sensitive data will never be seen directly by the student network
As the teacher has learned from the sensitive data, gaussian noise is injected into the hint and the distillation losses before being backpropagated to update the student
Conclusion
Model distillation is likely to become a useful method for model compression, it differs from other methods such as pruning and quantization because it changes model architecture.
There is no established standard for model distillation yet, it is currently a more research-oriented field. However, the technique is likely to mature as deploying models on mobile devices become more commonplace.
Considering the privacy and IP issues that arise with directly releasing models, frameworks such as RONA that bring privacy guarantees will become a key tool.