Fairness in Machine Learning
This article was written by Mickael Fine for season 8 of Data For Good.
This article attempts to clear up the complex and vast subject of fairness in machine learning. Without being exhaustive, it proposes a certain number of definitions and very useful tools that every Data Scientist must appropriate in order to address this topic.

Use of machine learning is progressing fast around us. For a few years now, many companies and institutions have been starting to realize the hidden richness of their data and have developed projects to exploit that potential.
Today, since quite some time, algorithms have had an impact on our lives, from very minor ones (the ads we see while browsing, or the films recommended to us in Netflix) to major ones (being selected for a job interview, for a school admission, ...). Insurance companies have been using algorithms for a long time to determine the fees they apply to individuals, based on age, health condition and other criteria.
How can we know we are treated fairly by those algorithms compared to all the other persons around us? Do the developers know whether they inject biases in their algorithms ?
That field of study emerged recently, and we’ve seen articles on trustworthy AI popping-up everywhere, covering several topics, such as:
Non-Discrimination
Respect for Privacy
Robustness
Safety
Transparency
The present article is dealing with non-discrimination, fairness of machine learning and tips for data scientists to improve their work to build a fairer AI.
First of all, what do we mean by fairness? It’s a very tricky point.
Researchers, politicians, and any people involved in the subject do not offer a consensual definition of fairness. There are indeed many types of fairness that could be used, as we’ll see later in this paper. Also, each type of fairness requires technical and non-technical decisions and trade-offs, which are not easy to put in place.
Discrimination
Discrimination is defined as the unfair or prejudicial treatment of people and groups based on criteria such as:
Age
Disability
Language
Name
Nationality
Political orientation
Race or ethnicity
Region
Religious beliefs
Sex, sex characteristics, gender, and gender identity
Sexual orientation
The list is very long, as it encompasses any characteristic that can be used to treat individuals in a different way.
As a human being, it is not always easy to identify biases, or see when someone is treated differently from another person. We always perceive things from our personal biases, which come from our personal history, our culture, our moral, our opinions, …
The COMPAS example
In 2016, the US criminal risk assessment software named COMPAS was analyzed and the researchers found out that a major racial bias was built in the algorithm. This product was used to predict the risk of a criminal reoffending by generating a recidivism risk score. The results were showing a bias in favour of white people (black people predicted risk to be a criminal was much higher than the one of white people).




https://www.propublica.org/article/machine-bias-risk-assessments-in-criminal-sentencing
https://www.ted.com/talks/joy_buolamwini_how_i_m_fighting_bias_in_algorithms
But is that so simple ?
Many papers have been published on this Compas topic, and some of them show that the issue is not only in the creation of the algorithm, but also in its use, and that’s all the complexity.
As a matter of fact, we’ll see that later in this article, an algorithm can not satisfy all fairness criterias, and the metrics used to create the algorithm must be fully understood to correctly use it.
The Compas algorithm was built to meet “Predictive parity” fairness criteria and was not meant to satisfy all fairness metrics (which is not possible). The recidivism score should not have been used to classify people without a deep assessment of their social situation. The fairness metric used should have been more understood by the U.S. criminal authorities to apply the algorithm with more fairness.
If you are interested to know more about researches on this subject, you can refer to the two following papers, which demonstrate the complexity of building the right algorithm:
There are many other examples of discrimination.
Several articles have been published on this topic.
The Apple Card example
Another explicit example bringing huge discrimination is the Apple card grant mechanism, illustrated by the following tweets:

There are many illustrations where such a behavior happens.
Why can this happen?
How can a developer know he/she is introducing a bias in his algorithm ?
When we talk about an algorithm used in production, we talk about a data product. And to understand and give some clues on how to improve the fairness of an algorithm, it is important to come back to the basis of what is a data product.
The lifecycle of a data product can be modeled in 2 major steps:

Model creation, involving:
The construction of a model with parameters
A set of data to train the model (or several sets)
Model activation (use of the model) :
New data on which the model will be applied
KPI to determine how the model is behaving
Model creation
A model is basically a function with parameters. It will be fed with data and will give an output.

The parameters which will be determined at the creation of the model are heavily linked to the data used to train the algorithm.
Inferences created within the model will reflect the information contained in the training data.
The data sets used are by definition a partial representation of the reality. They are likely to include biases, such as human cognitive biases (which directly reflect the biases of the humans), or collection biases (such as data coming only from a single country for a data product that will be used worldwide).
A data set can be biased in so many ways, and models built from biased data sets are so much likely to create discriminations between different populations (such as a data product granting less loans to women than men because it is based on historical work data).
Model activation
Once the model is in production and used in a real life application, it will predict outcomes based on data that had never been seen before.
The only means for a data scientist to understand whether the trained model will include a bias for certain populations, is by building metrics around the model. Several researches have started to identify and categorize those metrics. To understand them, let’s take a look at the various definitions of fairness.
BIAS
2 main types of biases can be considered:
Cognitive bias
Machine learning (statistical) bias
Cognitive bias
The main origin of bias are us, human beings. We are full of biases. Biases coming from our history, our culture, our opinions, our morality, lack of knowledge of a specific domain...
There is a huge literature on cognitive bias. Major cognitive bias can be: stereotyping, selective perception and confirmation bias, and so many. The following paper give a very nice and in depth visualisation of cognitive biases: https://www.sog.unc.edu/sites/www.sog.unc.edu/files/course_materials/Cognitive%20Biases%20Codex.pdf
Machine learning bias
Machine learning biases generally come from problems introduced by the person who designs and/or trains a model. The developers could either create algorithms that reflect unintended cognitive biases or real-life prejudices. They could also introduce biases because they use incomplete, faulty or prejudicial data sets to train and/or validate their models.
We are one of the main reasons why biases appear in the creation of an algorithm. Why do we choose a certain data set to train an algorithm. Have we done a thorough analysis about a training data set to ensure we limit the biases it will bring to the algorithm?
https://lionbridge.ai/articles/7-types-of-data-bias-in-machine-learning/
Although these biases are often unintentional, the consequences of their presence in machine learning systems can be significant. Depending on how the machine learning systems are used, such biases could result in lower customer service experiences, reduced sales and revenue, unfair or possibly illegal actions, and potentially dangerous conditions.
Let’s take an example to quickly understand the concept of bias. A data scientist trains a model on the sample on the left in the below image to build a data product that will be applicable to the population on the right.


Here, we have a “sample bias”, or “selection bias”, with outcomes predicted by the model not taking into account the right representativeness of characteristics within the population.
Another example of this is certain facial recognition systems trained primarily on images of white men. These models have considerably lower levels of accuracy with women and people of different ethnicities.


I invite you to read the following article on Joy Buolamwini, who was at the origin of the above study: https://www.fastcompany.com/90525023/most-creative-people-2020-joy-buolamwini
Her research helped persuade Amazon, IBM and Microsoft to put a hold on facial recognition technology.
There are many more biases than this single and simple one. A bias can be for exemple classified in several categories, and relate to various parts of the data product lifecycle, as you can see in the following image.

Definitions of Fairness
Algorithm fairness has started to attract the attention of researchers in AI, Software Engineering and Law communities, with more than twenty different notions of fairness proposed in the last few years. Yet, there is no clear agreement on which definition to apply in each situation. The detailed differences between multiple definitions are also difficult to grasp and definitions can be exclusive.
Several researches have worked on the subject and tried to define fairness from a mathematical point of view. In the following research paper https://fairware.cs.umass.edu/papers/Verma.pdf and in several other documents & articles, we can see that the definition of fairness is not unique. In this paper, the researcher concluded:
“ .. is the classifier fair? Clearly, the answer to this question depends on the notion of fairness one wants to adopt. We believe more work is needed to clarify which definitions are appropriate to each particular situation. We intend to make a step in this direction by systematically analyzing existing reports on software discrimination, identifying the notion of fairness employed in each case, and classifying the results ”.
You can also find in the the following papers detailed descriptions of bias and fairness definitions that are quite commonly agreed upon:
https://arxiv.org/pdf/1908.09635.pdf
https://arxiv.org/pdf/1710.03184.pdf
https://fairmlbook.org/tutorial2.html
The most used fairness definitions relate to the one given in the below tables, applicable to a group or to an individual :

Not all definitions are compatible with the others. Some are exclusive of the other (like equalized odds and demographic parity, see the explanation below of the 3 main definitions). A company, or organization, will have to decide which definition applies to its product(s).
Aequitas (A DSSG initiative) has issued an excellent view of fairness definitions :
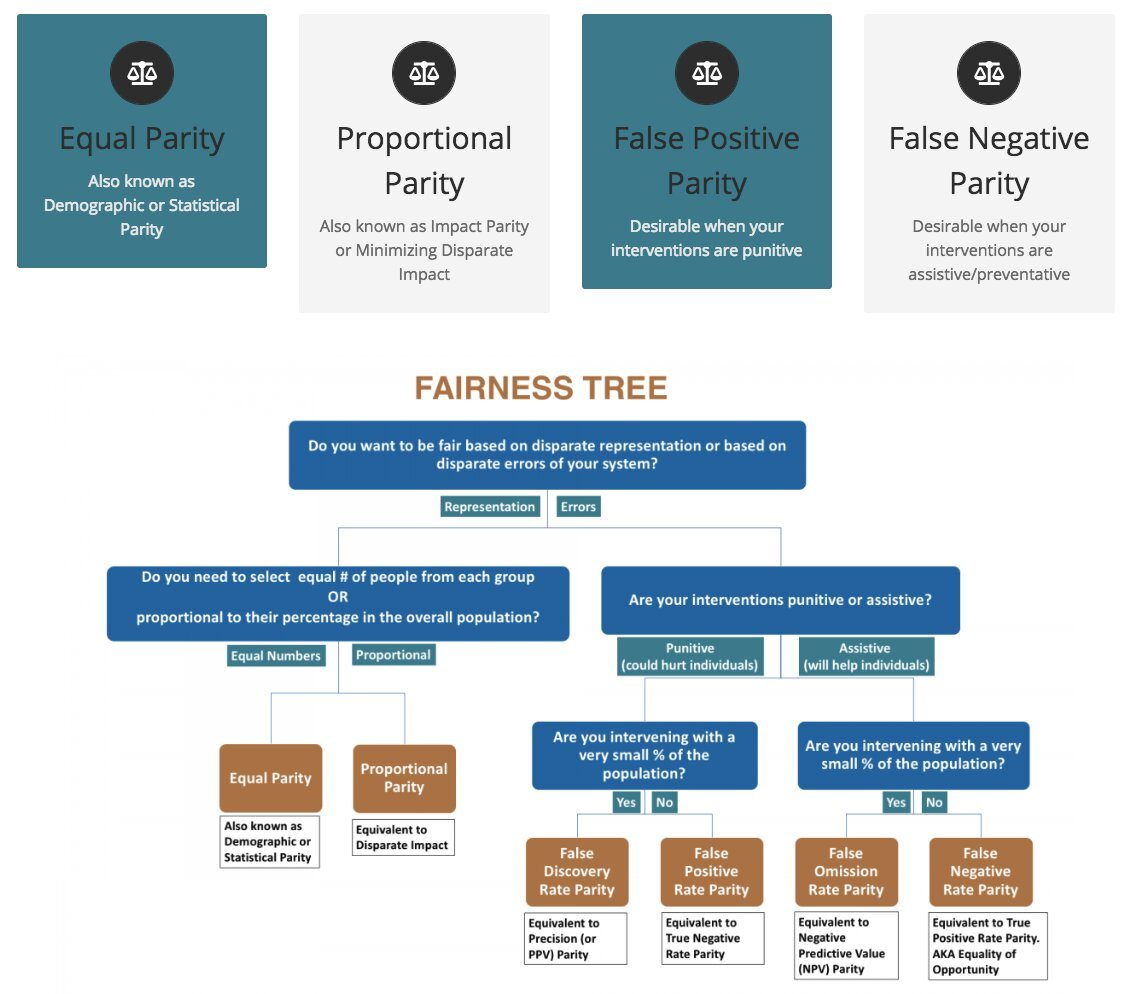
Let’s focus on the most common fairness in use:
Demographic parity,
Equality of Opportunity
Equalized Odds
Let’s take a binary parameter (0/1), G (ex: gender), that we want to protect from algorithm discrimination. To simplify, let’s consider only G as a parameter. We’re dealing with two groups:
one is considered protected (ex: male group)
the other one unprotected (female group)
Then we consider the result of a binary classifier. One of the output classes is considered a positive outcome (ex: getting hired) and the other one a negative outcome (ex: not getting hired).

In complex data products, we are usually not dealing with one single algorithm, there can be several used in cascade or in parallel. The complexity to mitigate biases can be huge.
Bias mitigation & Fair Machine learning tools and libraries
While we find a lot of research papers on fairness, direct solutions and tools for developers are quite scarce at the moment being.
Major libraries, such as Scikit-learn, do not embed fairness metrics. But some big players like Google or IBM, or isolated initiatives have started to propose interesting approaches.
Most of them fall into three categories:
Preprocessing
Optimization at training time
Post-processing
In the following Table, you can find some indications of which category would apply to a machine learning algorithm or process. For additional details, I invite you to go through the following paper: https://arxiv.org/pdf/1908.09635.pdf.

How to prevent bias
Awareness and good governance can help prevent machine learning bias.
An organization that takes into account biases potentiality in their data products from the early phase in their products conception will be better equipped to combat any bias that could be implemented.
Setting best practices would require:
Define a fairness policy within the company to assess and define which fairness metric(s) should be applicable to the company and its products. This would give the main direction and set expectations.
Include fairness metrics in the initial phase of any data product conception to ensure the company is able to mitigate any risks on fairness
During the development phase; select training data that is appropriately representative and large enough to limit the occurrence of usual machine learning bias (like sample bias or prejudice bias).
Test deeply to ensure the outputs of the data product don't reflect bias due to the training data sets or model.
Monitor data products as they are used in production to ensure biases don’t appear over time, as the algorithm will be used on new data never seen during the training phase. During that phase, it’s important to identify any pattern that would suggest a possible bias.
Use additional resources that we’ll describe in the following part of this article to examine and inspect models.
Machine learning Fairness Tools
The literature on fairness has increased a lot since 1 or 2 years ago. But the libraries or tools that developers and data scientists can use are still scarce.
You’ll find in the following part an overview and comparison of these resources.
https://www.linkedin.com/pulse/overview-some-available-fairness-frameworks-packages-murat-durmus/
https://analyticsindiamag.com/top-tools-for-machine-learning-algorithm-fairness/
The various tools offer specific metrics, visualisation and comparison capabilities. They either offer a scalable and efficient implementation of SHAP, or are nicely paired with SHAP.
(SHAP is based on the concept of the Shapley value from the field of cooperative game theory that assigns each feature an importance value for a particular prediction).
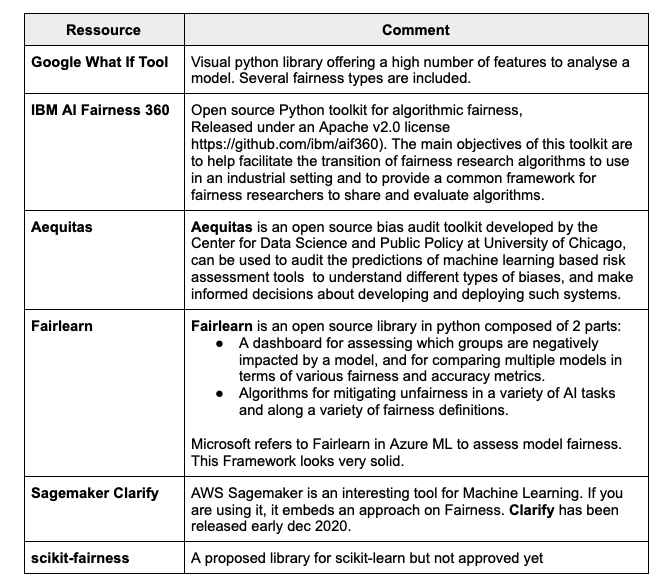
Google What If Tool
Google has put in place some very interesting resources to better understand fairness optimization, and visualize fairness metrics.
As a first interesting approach, I really invite you to play with the following page, where you will see that optimizing for fairness might reduce the overall performances of the model. It will then be a conception choice based on the sensitivity of the model to variables being a proxy of protected variables. https://research.google.com/bigpicture/attacking-discrimination-in-ml/
What If Tool is a visualization tool that can be used in a Python notebook to analyze an ML model.
The following website give a quick overview with demos about the tool capabilities:
https://pair-code.github.io/what-if-tool/index.html#demos
https://pair-code.github.io/what-if-tool/ai-fairness.html
You’ll find as well a very good introduction to the use of WIT and SHAP for fairness optimization: https://colab.research.google.com/github/PAIR-code/what-if-tool/blob/master/WIT_COMPAS_with_SHAP.ipynb
https://pair-code.github.io/what-if-tool/learn/tutorials/features-overview-bias/
IBM AI Fairness 360
https://arxiv.org/abs/1810.01943
https://github.com/Trusted-AI/AIF360
AI Fairness 360 Python package includes a comprehensive set of metrics for datasets and models to test for biases, explanations for these metrics, and algorithms to mitigate bias in datasets and models.

FAIRLEARN
The most complete Framework
Fairlearn offers a couple of tools that help you detect and mitigate unfairness in your models. There are two main components in the fairlearn package:
Assessing fairness: Fairlearn offers a Dashboard component and a set of metrics to help assess the fairness of a model.
Mitigating unfairness: Along with the dashboard and metrics, Fairless offers several algorithms that can be used to mitigate models discrimination (training or post-processing)
WIth Fairlearn, you will be able to :
Measure fairness using the fairlearn dashboard widget.
Improve fairness for trained models using TresholdOptimizer
Train models with improved fairness using GridSearch
The following article gives a detailed overview of Fairlearn : https://medium.com/microsoftazure/fairlearn-the-secret-to-teaching-your-models-to-play-fair-1dfe8a42ed9f
Full resources available at:
https://github.com/wmeints/fairlearn-demo
https://fairlearn.github.io/master/index.html
Sagemaker Clarify
AWS announced early december 2020 their new module in Sagemaker: Sagemaker Clarify.
This is very useful for all data scientist working in Sagemaker, as they’ll be able to :
Measure and assess
Schedule Clarify bias monitor to monitor predictions for bias drift on a regular basis.
Schedule Clarify explainability monitor to monitor predictions for feature attribution drift on a regular basis.
You’ll find the complete module there : https://aws.amazon.com/sagemaker/clarify/
You’ll find at the following page, a detailed step-by-step approach to apply some of the above tools to the Compass data: https://medium.com/sfu-cspmp/model-transparency-fairness-552a747b444
Bibliography
The literature on ML fairness is starting to be quite important.
If you want to know more, you can refer to the following articles & papers:
https://towardsdatascience.com/a-tutorial-on-fairness-in-machine-learning-3ff8ba1040cb
https://towardsdatascience.com/programming-fairness-in-algorithms-4943a13dd9f8
https://towardsdatascience.com/machine-learning-and-discrimination-2ed1a8b01038
Racial Influence on Automated Perceptions of Emotions: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3281765
Very detailed paper : Social Data: Biases, Methodological Pitfalls, and Ethical Boundaries https://pdfs.semanticscholar.org/143c/0caaa1eb79a59a8422d392459bd303268d1f.pdf?_ga=2.108265734.586782849.1607854058-468093263.1606495306
https://towardsdatascience.com/machine-learning-and-discrimination-2ed1a8b01038
Resources in French
If you want to go further, you can refer to the following training materials:
Video tutorials
Course materials